
 English
English 中文
中文 العربية
العربية español
español

Introduction
A coolant distribution unit (CDU) is the control boundary between your facility heat-rejection loop and the IT-side liquid loop. In AI/HPC environments, that boundary matters because it sets the limits for temperature stability, flow control, filtration, and—ultimately—how safely you can run high-density racks.
This guide is built for 2026 realities: mixed-density halls, aggressive capacity adds, and tighter scrutiny on PUE/WUE. The goal is to help you choose the best CDU for data center AI racks without introducing new failure modes that threaten uptime.
To use this guide well, have four inputs ready:
-
Density forecasts by rack and by cluster (12–24 months)
-
Your target ΔT (and any warm-water targets) for the IT loop
-
Water chemistry requirements and who owns them (facilities vs vendor)
-
An integration map (BMS/DCIM, alarming, and telemetry destinations)
Key Takeaway: Treat CDU selection as an uptime and integration decision first, and a “cooling capacity” decision second.
Define the load
This section helps you choose the best CDU for data center AI racks by turning compute plans into hydraulic and risk requirements.
Rack and cluster densities
Start with two numbers, not one: the rack peak and the cluster peak.
-
Rack peak drives the cooling method and the local risk profile (what happens when a single rack loses flow).
-
Cluster peak determines whether you can afford many small failure domains (rack CDUs) or need consolidated distribution (row/hall).
If your AI footprint is growing, plan for step changes—not a smooth curve. Procurement and construction cycles rarely line up with model training demand.
Cooling method fit
Your CDU choice is constrained by how you remove heat at the rack:
-
Rear-door heat exchangers (RDHx) can be a practical bridge for mixed halls because they remove heat from exhaust air without requiring direct-to-chip plumbing on every server. They still need disciplined loop control and can push you into row-level distribution earlier than you expect. (See Mirantis’ framing of RDHx and CDU roles in Mirantis’ overview of CDUs in liquid cooling methods.)
-
Direct-to-chip raises the bar on filtration, flow stability, and instrumentation because cold plates and microchannels punish chemistry drift.
-
Immersion changes your service model and containment strategy; the CDU may be upstream of heat exchangers tied to tanks.
The point isn’t “pick the newest method.” It’s to align CDU architecture with what your operations team can maintain predictably.
Capacity headroom
Headroom is where many CDU projects fail quietly.
Two operator-friendly rules:
-
Size for the next deployment step, not today’s average utilization.
-
Keep headroom in both heat transfer (kW) and hydraulics (flow and pump head). A CDU that can move the heat but can’t maintain stable flow at the rack is a reliability problem, not a performance win.
Choose the architecture
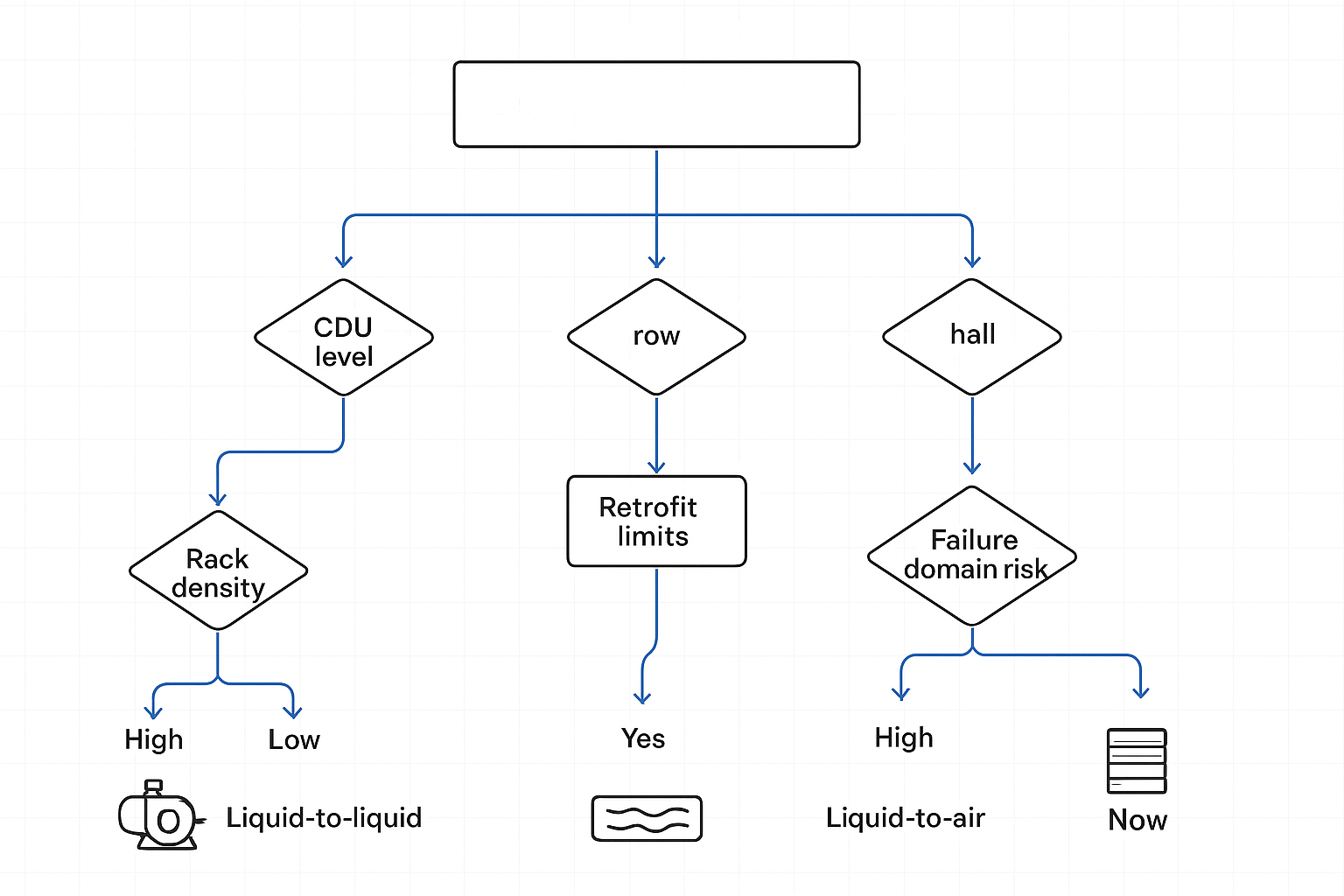
Rack vs row vs hall level
Pick the CDU level by optimizing for failure domain and retrofit constraints.
If you’re evaluating CDU architecture (rack vs row vs hall), start by deciding how much shared risk you can accept per AI pod.
-
Rack-level CDUs localize outages: if a CDU fault takes down one rack, your blast radius is small. The trade-off is unit count, rack space, and a more repetitive maintenance burden.
-
Row-level CDUs reduce the number of units and can scale in a modular way, but they create shared risk if you don’t design isolation and redundancy correctly.
-
Hall/gallery CDUs centralize control and can scale to very large deployments, but they assume a higher operational maturity—especially around commissioning, alarm tuning, and change management.
For a concise taxonomy of these trade-offs, see Vertiv’s CDU architecture comparison.
Heat rejection choice
Your CDU architecture also depends on where the heat goes after it leaves the IT loop.
If you’re comparing a liquid-to-liquid vs liquid-to-air CDU, align the choice with mechanical capacity and retrofit constraints:
-
Liquid-to-liquid (IT loop to facility water) is common at larger scales because it cleanly isolates the IT loop and leverages existing heat rejection systems.
-
Liquid-to-air can be a practical option where facility-water capacity is constrained or where you’re staging a deployment before mechanical plant upgrades.
In mixed-density retrofits, be realistic about what you can install without destabilizing existing operations. As DataCenterKnowledge notes, decisions should match density bands and retrofit limits—not hype (DataCenterKnowledge on choosing AI cooling architectures without hype (2026)).
Failure domain and risk
In 2026, CDU selection is often a risk segmentation problem.
Ask these three questions:
-
If a CDU is out of service for two hours, what exactly goes dark—a rack, a row, or an entire AI pod?
-
Can you isolate that domain with valves and controls without draining the whole loop?
-
Will your alarm strategy detect issues early enough to act before GPU throttling becomes an incident?
Hydraulic and thermal design
Flow and pump head
Hydraulics is where “works on paper” becomes “works at 2 a.m.”
What to validate:
-
Required flow at the rack across expected workload swings
-
Pump head margin after you account for filters, quick disconnects, manifolds, and elevation changes
-
Control stability: can the system track setpoints without oscillation when loads change quickly?
A practical pump lesson: cavitation and poor sizing don’t announce themselves with a single failure; they show up as vibration, noise, and degraded control. For an operator-friendly overview of sizing and monitoring considerations (including NPSH), see Wilo on the critical role of pumps in data center cooling (2025).
ΔT and approach temperature
ΔT targets should be set with a single intent: stable component temperatures with a controllable efficiency envelope.
-
If you’re planning warm-water operation, you’re effectively choosing an operating strategy that trades lower mechanical energy for tighter control requirements.
-
Approach temperature matters at the boundary between loops. A CDU that can’t maintain a predictable approach under transient load will force you to widen setpoints “just to be safe,” which erodes the efficiency you were chasing.
Materials and coolant
Materials and chemistry are inseparable.
Operator checklist:
-
Confirm wetted materials across plates, seals, manifolds, and any aluminum/copper interfaces.
-
Define the coolant spec (water, water/glycol, additives), plus sampling cadence and acceptance limits.
-
Decide who owns filtration and bioload control, and how alarms route when chemistry drifts.
ASHRAE and OCP guidance commonly emphasizes the need for disciplined liquid management and temperature classifications as liquid cooling scales (see OCP Cooling Environments and ASHRAE TC9.9 (2024)).
Reliability and redundancy
Pumps and power feeds
Treat pump redundancy and power feeds as a matched pair. For AI pods, this is the core of data center liquid cooling redundancy.
What to require in an RFP:
-
Redundant pumps (N+1 at minimum for critical pods)
-
Independent power feeds where your facility architecture supports it
-
Clear failure behavior (what happens on sensor loss, pump fault, or low-flow condition)
For deployment-oriented practices, see Vertiv on deploying and managing CDUs (2024).
Leak detection and containment
Leak detection should be layered, not single-sensor.
Look for:
-
Point/cable sensing at connectors, drip pans, and serviceable components
-
Pressure and flow trending that can catch “slow leaks” or air ingress
-
A containment plan that matches your operational reality (who responds, how fast, and what is isolated)
Segmentation and isolation
Segmentation is your insurance policy.
-
Use isolation valves and serviceable branches so you can maintain pumps, filters, or heat exchangers without draining large parts of the system.
-
Align segmentation with how you deploy AI: pods, rows, or clusters that can be isolated without turning every maintenance activity into a major change window.
Pro Tip: Write “what can be isolated without draining?” into your acceptance criteria. It is more predictive of uptime than another kW number.
Controls and interoperability
Telemetry and alarms
For AI racks, telemetry isn’t “nice to have.” It’s how you avoid expensive surprises.
At minimum, plan to collect:
-
Supply/return temperatures (facility side and IT side)
-
Flow rate per branch (or per manifold) and pump speed
-
Differential pressure across filters/critical components
-
Leak detection states and alarm history
Then decide what counts as:
-
An operator ticket
-
An automated protective action
-
A commissioning “stop ship” condition
BMS/DCIM protocols
Protocol support isn’t just a checkbox—it determines how fast you can integrate CDU data into your existing operational playbooks, and it’s central to BMS/DCIM integration for CDUs.
Coolnet guidance (≤30 words): Coolnet recommends open interfaces—Modbus RTU (RS‑485) with optional TCP/IP—so CDU telemetry and alarms can feed DCIM/BMS for unified trending, capacity planning, and incident response.
For internal reference on Coolnet CDU positioning, see Coolnet.
Capacity planning linkages
Treat CDU telemetry as a capacity planning input, not a postmortem artifact.
Link the data to:
-
Rack and pod growth forecasts
-
Heat rejection constraints (tower/chiller limits)
-
Operating setpoints and where you’re sacrificing efficiency for stability
If you can’t trend it, you can’t plan it.
Deployment and O&M
Placement and footprint
Placement is a reliability decision.
Validate:
-
Service access for pumps, filters, and heat exchangers
-
Pipe routing that avoids single points of damage and supports isolation
-
Drain/fill points that don’t require “creative” temporary hoses in production areas
Commissioning sequence
Commissioning should prove three things before you trust the system:
-
Hydraulic performance: flows and ΔP match design across the range of expected operating states.
-
Control stability: setpoint changes don’t induce oscillations or temperature swings.
-
Failure behavior: pump failover, sensor faults, and leak alarms trigger the intended responses.
Document baseline telemetry on day one. You’ll need it to spot drift.
Maintenance cadence
Plan a cadence that matches your risk tolerance and staffing:
-
Routine filter checks and ΔP trending
-
Chemistry sampling and log review
-
Pump health monitoring (noise, vibration, trending)
-
Alarm review to eliminate nuisance alerts before they train operators to ignore them
Compliance and sustainability
ASHRAE/OCP alignment
Use recognized guidance to standardize language in RFPs and O&M docs.
Two practical uses:
-
Temperature class targets and operating envelopes
-
Common expectations for reliability, filtration, and instrumentation
A starting point is the ASHRAE/OCP overview deck referenced earlier.
Water and chemistry logs
If you want stable performance, treat liquid logs like electrical single-lines: controlled, auditable, and current.
Minimum logging scope:
-
Make-up water events and volumes
-
Chemistry results (pH, conductivity, inhibitors, bioload indicators)
-
Filter changes and pressure trends
-
Leak events, responses, and corrective actions
Heat recovery options
If you can run at warmer supply temperatures, heat recovery becomes more realistic.
The selection question is simple: can your CDU and downstream loop control deliver stable temperatures that your recovery system can use without compromising IT inlet conditions?
Conclusion
A CDU selection process that works in 2026 is one you can defend in an RFP, operate under pressure, and scale without re-architecting every quarter.
-
Turn the criteria above into a shortlist and an RFP checklist: architecture level, heat rejection path, pump and power redundancy, isolation/segmentation, instrumentation, and chemistry ownership.
-
Validate performance with step‑load tests and baseline telemetry: prove control stability, failover behavior, and alarm routing before production.
-
Phase deployment to minimize downtime and lock in ROI: start with an isolated pod, standardize runbooks, then scale.
If you need a reference point for integrated CDU + monitoring approaches during evaluation, you can review Coolnet’s materials on CDUs and adjacent liquid cooling options, including its rear door heat exchanger solution.




 IPv6 network supported
IPv6 network supported